Storj-hosted S3 Compatible Gateway
The Storj globally distributed, multi-region cloud-hosted S3-compatible gateway
S3 compatibility
When Amazon launched its S3 service 15 years ago and created the cloud storage industry, it also unknowingly made object storage the standard for storing data in the cloud. Object storage organizes data into objects, which contain the data itself, its metadata, and a unique identifier. These objects are stored in buckets rather than a hierarchical system. Since then, the grand majority of cloud storage services have reinforced this interface, and the majority of people storing data in the cloud use similar architectures.
Amazon S3 is accessed via APIs, most of which rely on the HTTP protocol and XML serialization. By making a storage system compatible with these APIs, it makes it much easier for users to migrate to new services without much effort. All you have to do is point files to the new buckets and migrate any static data you’d like to keep. For example, core features such as basic upload and download, of course, should map quite easily to the new ecosystem, including systems like Storj. We support organizing objects by bucket and key, all HTTP verbs including HEAD, byte-range fetches, as well as uploading files in multiple parts.
See the latest S3-compatibility in the S3 compatibility table and S3-compatibility list of GatewayMT.
Security and encryption
Where the Storj network really excels compared to centralized providers is in its privacy and security, so we’d be remiss in not addressing these topics specifically as they pertain to S3.
The distributed security tokens (access grants) that Storj typically uses (via libuplink, etc.) contain too much detail to fit into an S3 access key or secret key field. Storj offers an S3-specific authorization service, which maps S3-compatible credentials to a Storj access grant. This service saves access grants encrypted into a database. The access grants are individually encrypted using information from the much shorter returned access key, which is not stored in our auth service. Access grants never remain decrypted longer than they are needed, and only a hash of the access key is ever persisted. In short, the system is designed to protect your data at rest.
Benefits
Overall, our S3 compatibility project has been a huge effort to address the needs of certain customers, making it easier than ever to migrate to the decentralized cloud. It should provide bandwidth-limited customers with more than three times faster access. It provides a drop-in replacement for S3 with the great majority of use-cases. Finally, it offers users the flexibility to dial in the balance of security versus accessibility, allowing access to files directly from web browsers in ways they never could before.
Usage
To save on costs and improve performance, please see Multipart Part Size.
There are two primary ways to get started using our hosted S3 gateway and get issued an S3 compatible access key, secret key, and endpoint.
Using via the Web interface
The first main way is to use the web wizard in the Satellite web interface. The web wizard is simple and easy to use, but lacks some configurability, like the ability to restrict to specific prefixes within a bucket or use a different auth service. If you need those features, consider the CLI, farther below.
After logging in, create a new access grant and select "continue in browser."
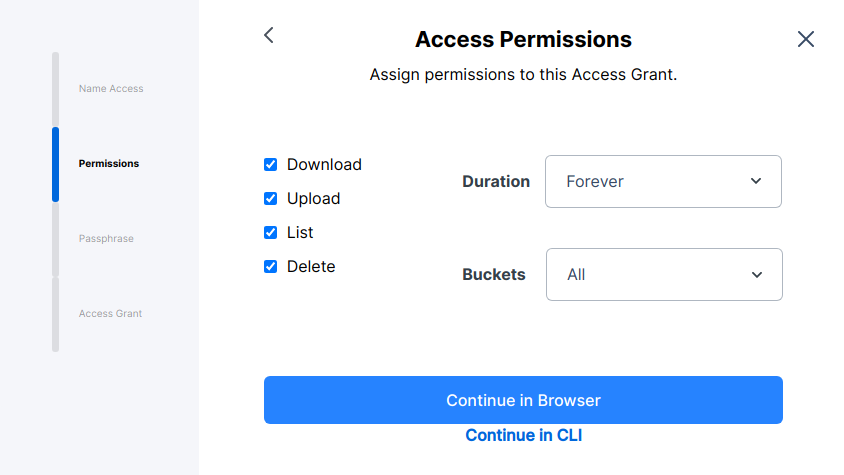
Once you have created an access grant, make sure to select the "Generate S3 credentials" option, at the bottom.
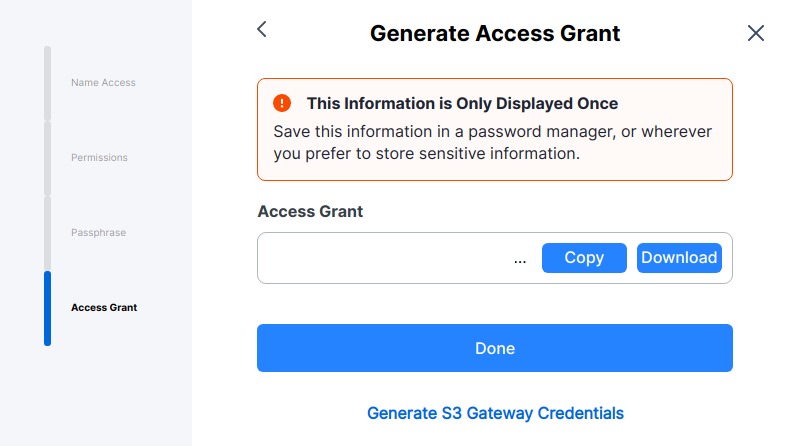
You can now use the generated access key, secret key, and endpoint in your AWS S3-supporting application.
CLI
The CLI is not as easy, but is more flexible in allowing you to control what specific encrypted paths the Gateway has access to. Via the Uplink CLI, you'll want to run the uplink share command with the --register option.
uplink share is a flexible command that allows you to restrict and generate new access grants with a variety of restrictions. By adding --register, the uplink will use the default --auth-service flag to determine where to exchange the restricted access grant for an access key, secret key, and endpoint.
Here is an example command that exposes read-only access to the gateway for one specific prefix in a bucket:
This will output an access key, a secret key, and an S3 compatible endpoint for you to use.
Regions and Points of Presence
We currently have hosted Gateways in several regional locations and expect to expand as needed. The Gateway endpoint https://gateway.storjshare.io is configured to automatically route the traffic from the instance closest to your location.
Source code
All of the code for this feature (and the auth service access key database) lives here: https://github.com/storj/gateway-mt. If you want to run your own multitenant gateway and encrypted database of access keys, please do, and let us know if you have any problems.
If you are looking to self-host, you should also consider the Self-hosted S3 Compatible Gateway, which is much easier to set up and run.